

Big Data Analytics und Datenqualität
Aufgrund schnell wachsender Mengen an strukturierten aber vor allem auch unstrukturierten Daten (Big Data) ist Datenqualität heute ein hoch relevantes Thema. So werden bspw. große Mengen an unstrukturierten Daten aus unterschiedlichen, verteilten Quellen in diversen Formaten gesammelt und analysiert (oft in Echtzeit), um relevante Erkenntnisse abzuleiten und unternehmerische Entscheidungen zu unterstützen. Damit die abgeleiteten Ergebnisse valide und wertstiftend sind, ist die Sicherstellung der Qualität der zugrundeliegenden Daten unabdingbar.
Konkret werden im Rahmen der Forschungsarbeiten quantitative Methoden und Modelle zur Messung, Steuerung und Verbesserung der Datenqualität entwickelt und evaluiert. Dabei werden folgende Ziele verfolgt:
- Entwicklung von Ansätzen zur Messung der Datenqualität strukturierter und unstrukturierter Daten: Es werden effiziente quantitative Ansätze zur Messung der Datenqualität für datenwertorientierte Qualitätsdimensionen (bspw. Korrektheit, Konsistenz, Aktualität, Vollständigkeit, Eindeutigkeit) entwickelt. Diese sollen aufgrund der z. T. enormen Datenmengen automatisiert anwendbar und für unterschiedliche Datenformate (z. B. strukturierte und unstrukturierte Daten) sowie verteilte Daten (z. B. unternehmensinterne und -externe Daten) geeignet sein.
- Entwicklung maschineller Lernverfahren zur Berücksichtigung der Datenqualität: Zur Analyse strukturierter und unstrukturierter Daten werden maschinelle Lernverfahren (weiter)entwickelt, um das gemessene Datenqualitätsniveau (vgl. 1.) methodeninhärent zu berücksichtigen. Diese Einbeziehung der Datenqualität führt nicht nur dazu, dass sich die ermittelten Ergebnisse (z. B. Klassen- oder Clusterzuordnung) sehr stark ändern können. Vielmehr wird auch die Güte der Ergebnisse abhängig von der Qualität der Inputdaten ermittelt und ausgewiesen, um Entscheidungen wesentlich besser und transparenter als bisher unterstützen zu können.
- Entscheidungskalküle zur Bewertung der Datenqualität und zur Planung von Maßnahmen: Es wird an Entscheidungskalkülen gearbeitet, die eine ökonomische Bewertung von Datenqualitätsmaßnahmen gerade auch im Kontext von Big Data erlauben. Dabei gilt es sowohl die Kosten als auch den Nutzen unter Berücksichtigung der Charakteristika von Big Data möglichst automatisiert zu ermitteln. Der Nutzen von Datenqualitätsmaßnahmen resultiert primär aus der besseren Entscheidungsqualität, die mit höherer Datenqualität einhergeht, wobei insbesondere der konkrete Anwendungsfall sowie die verwendeten maschinellen Lernverfahren zu berücksichtigen sind.
- Datenqualität in der Informationssicherheit: Die Bewertung und Verbesserung der Datenqualität ist im Kontext der Informationssicherheit besonders herausfordernd. Erstens sind die Auswirkungen einer guten versus schlechten Datenqualität speziell in der Informationssicherheit mit einer ungleich höheren Entscheidungsunsicherheit behaftet. Zweitens kommt hinzu, dass die Qualität der Datenbasis für die Analysen und Entscheidungen auch gewährleistet sein muss, selbst oder gerade wenn diese Datenbasis mehrere Unternehmen mit (anonymisierten) Sicherheitsvorfällen umfasst.
Einen Überblick über die Fragestellungen gibt folgende Abbildung:
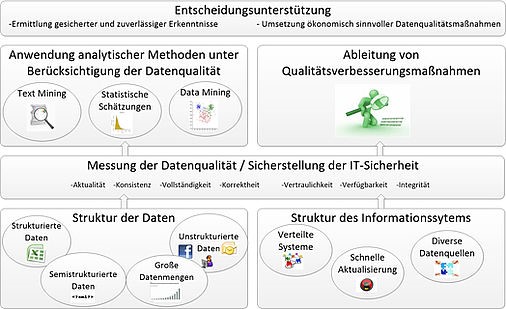
Abgeschlossene, laufende und zukünftige Forschungsprojekte:
- DQMM - Datenqualitätsmessung und -maßnahmen bei unstrukturierten Daten (2015-2018)
- IKZ - Internetkompetenzzentrum Ostbayern (2015-2021)
- DEVISE - Datenqualitätsmanagement zur Verbesserung der Informationssicherheit (2021-2024)
- DQMM@WIKI - Datenqualitätsmessung und -maßnahmen bei Wikis und Knowledge Graphen (2021-2024)
- DQNGI - Datenqualität bei textuellen, Nutzer-generierten Inhalten (2022-2025)
Armin Steinwender - 14.07.2022 15:56 
Lehrstuhl für Wirtschaftsinformatik II
Prof. Dr. Bernd Heinrich

Sekretariat
Tel.: +49 (0)941 943-6101
Fax: +49 (0)941 943-6120
E-Mail
Universitätsstraße 31
93053 Regensburg