Das Projekt versprach eine umfassende Analyse der zusammengesetzten Indefinitpronomen (ZIPs) in den slavischen Sprachen mit einem Fokus auf ihre Semantik. Unter ZIPs versteht man nichtkodifizierte und nicht vollständig grammatikalisierte reihenbildende Indefinitpronomen (IPs), die zahlreich in den slavischen Sprachen entstehen, aber systematisch noch nicht beschrieben worden sind. Analysiert wurden fünf Sprachen: Russisch (RU), Ukrainisch (UA), Kroatisch (HR), Polnisch (PL) sowie Tschechisch (CZ).
Das Projekt hatte also zwei Dimensionen. Die deskriptive Dimension des Projekts umfasste die Beschreibung der Semantik und Morphosyntax der ZIPs sowie die Erhebung von Daten zu ihrer Verwendungsfrequenz. Es wurden ZIPs in fünf slavischen Sprachen erstmals methodisch konsistent inventarisiert, indem sie aus den großen Webkorpora TenTen-Family (für RU, UA, PL und CZ) und hrWaC (für HR) extrahiert wurden. Als Nächstes wurden die extrahierten Reihen mit denselben Indefinitheitsmarkern (auch Modifikatoren genannt) nach dem Grad ihrer Grammatikalisierung charakterisiert und bewertet.
Die zeitaufwändigste Phase des Projekts war die Gewinnung der Korpusdaten für die semantische Karte der 2. Generation (SemKartIn), indem die ausgewählten zusammengesetzten Reihen (51 in allen fünf Sprachen) anhand der Webkorpora semantisch annotiert und die Frequenzdaten für jeweils 28 Verwendungskontexte verifiziert wurden. Zusätzlich wurden 100 zufällige Verwendungen jeder Reihe für die SemKartIn des 2. Typs nach Semantik und Distribution (33 Kontexte) manuell annotiert.
Parallel zu den deskriptiven Arbeiten wurde die theoretische Dimension des Projekts entwickelt. Ursprünglich sollte das Projekt mit den gesammelten Daten einen theoretischen Beitrag vor allem zum Ansatz der SemKartIn leisten. Darüber hinaus leistete das Projekt Beiträge zur Theorie der Grammatikalisierung und zur Lizenzierung von Polaritätseinheiten, die bei der Antragstellung nicht versprochen worden waren. Nach der Inventarisierung der ZIPs wurde klar, dass ohne eine fundierte Bewertung ihrer Grammatikalisierung keine weitere Arbeit möglich war: Die gesammelten Elemente zeigten eine sehr große Heterogenität in Bezug auf ihre Phonetik, Morphologie und Morphosyntax. Daher wurde eine Methode zur Messung des Grammatikalisierungsgrades von IPs entwickelt. Die nach Verwendungskontexten aufgeschlüsselten Frequenzdaten ermöglichten es, das Problem der Lizenzierung der IPs aus einer neuen Perspektive zu betrachten: Es wurde gezeigt, dass die Lizenzierung nur quantitativ erfolgt und dass es praktisch unmöglich ist, den Typ der IPs allein anhand ihrer Kontextdistribution eindeutig zu bestimmen.
Im Rahmen der Theorie der semantischen Kartierung wurde eine SemKartIn der Indefinitheit der neuen Generation entwickelt, die die eigentliche pronominale Semantik der ZIPs von ihren Verwendungskontexten trennt, andererseits aber Verbindungen zwischen beiden herstellt. Sie enthält auch angrenzende prä- und post-indefinite Bereiche. Diese Karte liefert Frequenzdaten und behebt die bekannten Schwächen der klassischen Karte der Indefinitheit von Haspelmath.
Die Forschung im Bereich der nicht-pronominalen Bedeutungskomponente der ZIPs ermöglichte die Erarbeitung einer Methodik zur korpusbasierten Identifizierung und präzisen Beschreibung der Evaluativität. Aufgrund der Komplexität der Entwicklung des Ansatzes konnte dieser leider nur auf tschechische ZIPs angewendet und noch nicht in die neue SemKartIn integriert werden.
In der letzten Phase wurde auf der Grundlage der SemKartIn eine sog. „weighted map“ der Indefinitheit der slavischen Sprachen erstellt, die die zentralen und peripheren semantischen Primitiva sowie die Stärke der Verbindung zwischen den einzelnen Primitiva darstellt. Die statistische Analyse der SemKartIn ermöglichte es, eine Verbindung zwischen präindefiniten und indefiniten Bedeutungen sowie zwischen semantischen Primitiva und einzelnen Kontexttypen herzustellen. Die Clusteranalyse, die in Bezug auf die semantischen Primitiva und die Verwendungskontexte durchgeführt wurde, ermöglichte die Identifizierung ähnlicher ZIPs in den analysierten slavischen Sprachen.
Team
Prof. Dr. Björn Hansen (Projektleiter)
Roman Fisun, M.A. (wiss. Miarbeiter)
Martina Rybová, M.A. (wiss. Mitarbeiterin)
Irina Maykova, M.A. (WHK)
Konsultanten:
Prof. Dr. Johan van der Auwera (U Antwerpen)
Dr. Natalia Levshina (U Leipzig)
Prof. Dr. Iryna Dudko (Nationale Pädagogische Hochschule Kiev)
Dr. Edyta Jurkiewicz-Rohrbacher (U Regensburg)
Prof. Dr. Petr Karlík (U Brno)
Wissenschaftliche Ergebnisse des Projekts
Projektziele und Ergebnisse
Das Projekt verfolgte vier konkrete Ziele:
Z1 Inventarisierung der ZIPs in fünf slavischen Sprachen,
Z2 empirische Überprüfung und Präzisierung der analytischen Primitiva auf der SemKartIn,
Z3 Überdenken der Struktur der klassischen Karte der Indefinitheit sowie ihre Erweiterung um angrenzende analytische Primitiva,
Z4 Erstellung einer weighted semantic map.
Zu Z1 wurden die Dissertation Fisun (2024), für das Kroatische der Artikel Fisun & Hansen (2025) sowie für das Ukrainische die Artikel Fisun (2019a, 2019b, 2023) vorgelegt.
Zu Z2 und Z3 liegen die Dissertationen Fisun (2024) und Rybová (2023) vor.
Zu Z4 wurde die Dissertation Fisun (2024) vorgelegt.
Zusätzlich zum versprochenen Output entstand im Rahmen des Projekts die veröffentlichte Masterarbeit von Maykova (2023). Frau Maykova unterstützte das Projekt insbesondere bei der Vorbereitung und Durchführung zahlreicher Korpusrecherchen. Ihre Einbindung in das Projekt, der Zugang zu den Zwischenergebnissen sowie die im Projekt erworbenen korpuslinguistischen Kompetenzen ermöglichten es ihr, die in der linguistischen Literatur verbreitete, bisher jedoch nicht belegte Hypothese zur Beschränkung von ZIPs auf bestimmte Sprachregister am russischen Material zu überprüfen.
Dissertation von Roman Fisun „Zusammengesetzte Indefinitpronomen in den slavischen Sprachen“ (Dispitation am 22.11.2024 in Regensburg)
Die Dissertation von Roman Fisun befasst sich mit der Inventarisierung, der Messung des Grammatikalisierungsgrades, der morphosyntaktischen Charakterisierung der ZIPs sowie mit der Erstellung der SemKartIn der zweiten Generation für RU, UA, PL, CZ und HR. Die in der Arbeit verwendeten Datenanalysen für HR wurden von Björn Hansen und für CZ von Martina Rybová durchgeführt. Den theoretischen Rahmen der Arbeit bilden die Grammatikalisierungstheorie, der referenzsemantische Ansatz und die Theorie der semantischen Kartierung.
Inventarisierung und Morphosyntax der ZIPs
Für die Inventarisierung der ZIPs bietet die Arbeit eine korpuslinguistische Methode, die für die verschiedenen möglichen Schreibweisen der ZIPs (getrennt, mit Bindestrich, zusammen) unterschiedliche Werkzeuge verwendet. Die so entstandenen Listen indefiniter Reihen bilden die ersten korpusbasierten Inventare für jede der untersuchten Sprachen. Es wurden 88 Reihen für RU, 78 für UA, 52 für PL, 53 für CZ und 32 für HR identifiziert.
Die extrahierten Modifikatoren wurden unter Berücksichtigung von zwei Aspekten morphosyntaktisch beschrieben. Zum einen wurde Haspelmaths semantisch-etymologische Klassifikation der Grammatikalisierungsquellen auf sie angewandt. Das slavische Material zeigte, dass die ursprüngliche Klassifikation aus sechs Quellentypen durch acht weitere Typen erheblich erweitert werden muss. Anschließend wurde die Ähnlichkeit der analysierten Sprachen in Bezug auf die Quellen der Grammatikalisierung bewertet. Die statistische Analyse ergab, dass die Modifikatoreninventare von UA–PL sowie RU–UA hinsichtlich der Repräsentation einzelner Quellentypen am nächsten beieinander liegen, während UA–HR, PL–HR und CZ–HR die geringste Ähnlichkeit aufweisen. Hinsichtlich der Entwicklung lexikalisch paralleler Modifikatoren liegen RU und UA am nächsten beieinander. Alle anderen Sprachpaare weisen eine deutlich geringere Ähnlichkeit auf.
Zum anderen wurde festgestellt, dass auch die Theorie von zwei morphosyntaktischen Typen der ZIPs gründlich überarbeitet werden muss. Bisher wurde postuliert, dass präponierte Modifikatoren auf Sluicing-Konstruktionen und postponierte Modifikatoren auf Relativsätze zurückgehen. Der neu vorgeschlagene Ansatz wurde als dynamisch bezeichnet: Die Analyse der Sprachdaten zeigte, dass synchron Konstruktionen mit unterschiedlichen Graden bzw. unterschiedlichen Phasen und Zwischenphasen der Grammatikalisierung parallel funktionieren. Dementsprechend lassen sich alle ZIPs in vier Typen gruppieren. Während unvollständige Relativsätze tatsächlich einen dieser Typen bilden, wird die Sluicing-Hypothese für präponierte ZIPs widerlegt.
Grammatikalisierungsgrad
Zur Bewertung der Grammatikalisierung der einzelnen Elemente entwickelte Fisun eine Methode zur Ermittlung eines speziellen Grammatikalisierungsscores. Dieses Maß wird anhand von 15 Grammatikalisierungskriterien berechnet, die auf den bekannten sechs Grammatikalisierungsparametern von Lehmann basieren. Die Auswertung aller ZIPs nach diesem Grammatikalisierungsscore und die statistische Analyse zeigten, dass der Grammatikalisierungsgrad der ZIPs positiv mit der Frequenz korreliert, aber nicht mit den Assoziationsmaßen in den Kollokationen Modifikator-*k-Wurzel (bei Getrenntschreibung). Die intuitive Vermutung, dass kodifizierte IPs stärker grammatikalisiert sind als nichtkodifizierte ZIPs, wurde im Wesentlichen bestätigt.
SemKartIn der zweiten Generation
Für die Erfassung der Semantik der ZIPs entwickelte Fisun ein neues Beschreibungsmodell (s. Abb. 1), das die semantischen analytischen Primitiva (semantischer Bereich der neuen Karte) inklusive angrenzender Gebiete mit ihren Verwendungskontexten verbindet (distributioneller Bereich der Karte). Darüber hinaus ermöglicht der entwickelte Ansatz die Darstellung quantitativer Informationen auf der Karte. Damit entspricht die neue Karte den Kriterien der semantischen Karten der zweiten Generation.
Die semantische Domäne der Karte wurde gegenüber der klassischen Karte von Haspelmath verfeinert und auf sieben semantische Primitiva reduziert: „specific known“, „specific unknown“, „general existential“, „existential quantification“, „universal quantification“, „free choice“ und „random choice“. Die angrenzenden Gebiete werden durch prä-indefinite und post-indefinite Funktionen (sog. off-map-Funktionen) repräsentiert. Als Grundlage für den distributionellen Teil der Karte wurden die in der Literatur für RU entwickelten 27 Kontexte der aufgehobenen Assertion (KaA) sowie zwei assertorische Kontexte auf alle Sprachen extrapoliert und als CQL-Abfragen formalisiert (für HR zusammen mit Björn Hansen und für CZ zusammen mit Martina Rybová). Die Kontexte sollten gemäß der Theorie folgende Klassen von IPs unterscheiden: spezifische IPs, NSIs, NPIs, FCIs.
| specific | NSI | NPI | FCI | |
| Assertorische K. | + | - | - | |
| 1.1. Direkte Negation | - | + | ||
| 1.2.1 N. des übergeordneten Infinitivs | - | |||
| 1.2.2. Übergeordnete N. mit Konjunktionen | - | |||
| 1.3.1. implizite N. I | - | + | ||
| 1.3.2. implizite N. II | - | + | ||
| 1.4. Prädikat der Irrealität mit impliziter N. | + | |||
| 1.5. Präpositionen mit impliziter N. | - | + | ||
| 1.6. Vorzeitigkeitskonstruktion | + | |||
| 2. NP mit Mengequantor der Existenz | ||||
| 3. Usuelle und iterative K. | - | + | ||
| 4.1. Konditionalsatz | ||||
| 4.2. Konstruktion mit Adverbialpartizip | + | |||
| 4.3. Konditional | ||||
| 4.4. K. mit dem Begrenzer | ||||
| 5.1. Entscheidungsfrage | ||||
| 5.2. Ergänzungsfrage | ||||
| 6. Disjunktion | - | + | ||
| 7.1. Möglichkeit | + | - | + | |
| 7.2. Notwendigkeit | + | - | + | |
| 8. Futur | + | - | + | |
| 9.1. Wunsch | + | - | + | |
| 9.2. Bitten, Vorschläge, Imperativ | + | - | + | |
| 9.3. Erlaubnis, Zusage, Zugeständnis | + | - | ||
| 10. Zweifel, Vermutung, Irrealität oder Meinung | + | - | + | |
| 11. Vergleich |
Tabelle 1. Kontexte der aufgehobenen Assertion und die von ihnen lizenzierten Pronomentypen
Pluszeichen stehen für besonders charakteristische Kontexte, Minuszeichen für keine Lizenzierung. Leere Zellen bezeichnen Kontexte, die IPs dieses Typs lizenzieren, dafür aber nicht besonders charakteristisch sind.
Auf der Grundlage dieses Beschreibungsmodells wurden semantische Karten von zwei Typen für 51 zusammengesetzte Reihen in fünf Sprachen erstellt. Für die Karten des ersten Typs wurden die 28 Kontexte im Korpus gezielt durchsucht. Da die erhaltenen Konkordanzen trotz sehr präziser Abfragen Rauschen enthielten und teilweise sehr groß waren, wurden für Konkordanzen mit mehr als 100 Treffern repräsentative Stichproben manuell bereinigt und die Ergebnisse auf die gesamte Konkordanzgröße extrapoliert (für HR von Björn Hansen und für CZ von Martina Rybová). Die erhaltenen absoluten Zahlen wurden nach der Frequenz der jeweiligen Reihe und der allgemeinen Frequenz des Kontextes in der jeweiligen Sprache normalisiert. Zu diesem Zweck wurde ein neues Maß entwickelt, das auf dem Assoziationsmaß „Pointwise Mutual Information“ basiert. Es ist nicht nur an die erhobenen Daten angepasst, sondern auch intuitiv interpretierbar, sowohl mathematisch als auch grafisch, was für die Kartierung von besonderer Bedeutung ist. Für jeden Kontext wurden eine oder mehrere zentrale semantische Funktionen identifiziert und entsprechende Verbindungen festgestellt. Die semantische Domäne gibt die Häufigkeit der Ausprägung der Funktion in den analysierten Kontexten an.
Ein Beispiel einer Karte des ersten Typs zeigt Abb. 1 für die PL-Reihe um popadło. Ihre Quellkonstruktion geht auf „no-matter“ zurück; off-map-Funktionen wurden nicht als zentral identifiziert. Die stärkste Funktion „random choice“ wird in acht Kontexten (sowohl im episodischen 0.1 als auch in KaA 1.3–10; keine Lizenzierung sichtbar) als zentral realisiert, während die Reihe als Reihe der freien Wahl nur in einem Kontext, nämlich 7.1 (Modalität der Möglichkeit), vorkommt. Das Maß 0,21 zeigt jedoch, dass dieser Kontext im Vergleich zu 1,02 für den assertorischen Kontext 0.1 nicht stark mit der Reihe assoziiert ist.
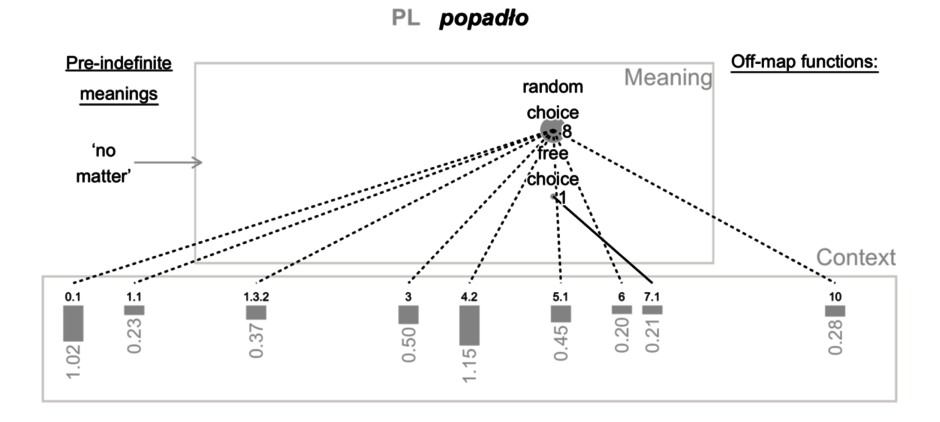
Abbildung 1. Neue SemKartIn des 1. Typs für die PL-Reihe um popadło
Für die Karten des zweiten Typs wurden zufällige Stichproben von 100 Verwendungen für dieselben 51 indefiniten Reihen analysiert, wobei für jede Verwendung eine semantische Funktion und ein Kontexttyp identifiziert wurden. Die Frequenzen auf der Karte des zweiten Typs sind absolute Zahlen; die Verbindungen zwischen einzelnen Funktionen und Kontexten werden ebenfalls dargestellt. Die Karten dieses Typs zeigen die tatsächliche Verteilung der häufigsten Funktionen und Kontexttypen.
Die Karte des zweiten Typs für die UA-Reihe um б (то) не було (Abb. 2) zeigt, dass sie neben ihrer Hauptfunktion der existenziellen Quantifizierung (63 von 100 Verwendungen) auch als Pronomen der freien Wahl und als Element der universellen Quantifizierung fungiert, letzteres nur im nicht-episodischen assertorischen Kontext 0.2. Ein beträchtlicher Anteil der Verwendungen entfällt auf sogenannte isolierte Konstruktionen: In 21% der analysierten Kontexte erfüllt die Reihe überhaupt keine indefinite Funktion. Die zentrale Funktion „existential quantification“ wird vor allem in verschiedenen Typen der Negationskontexte (1...) realisiert bzw. lizenziert. In der Stichprobe wird sie nicht im assertorischen Kontext registriert. Somit kann die UA-Reihe um б (то) не було in der Funktion „existential quantification“ als NPI identifiziert werden.
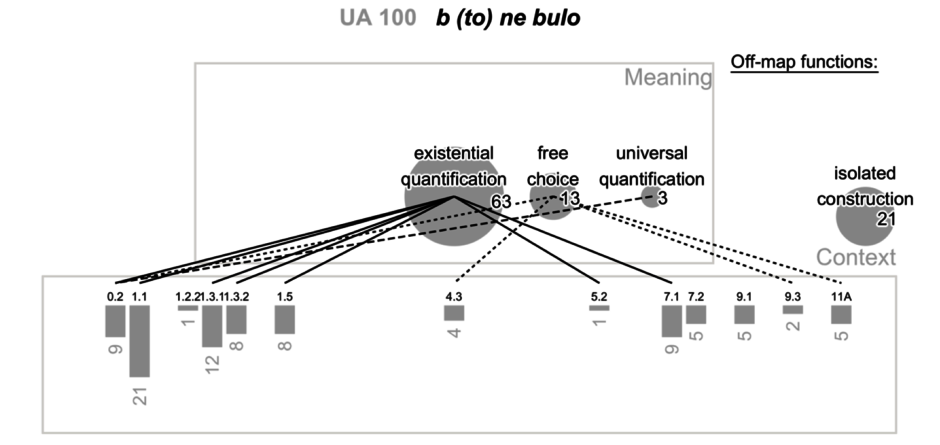
Abbildung 2. Neue SemKartIn des 2. Typs für die UA-Reihe um б (то) не було
Weighted map und theoretische Ergebnisse
Auf der Grundlage der einzelnen Karten wurde auch die sogenannte weighted map der slavischen Indefinitheit erarbeitet, die pronominale und off-map-Funktionen darstellt (Abb. 3).
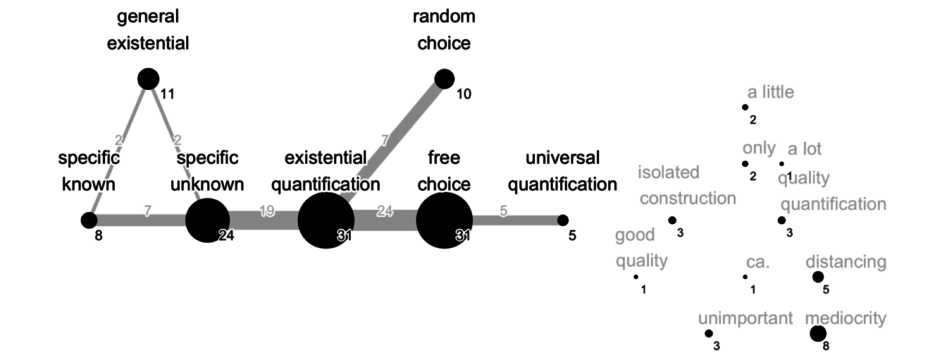
Abbildung 3. Weighted map der Indefinitheit in den slavischen Sprachen
Die Karte erlaubt es, zentrale („existential quantification“, „free choice“ sowie „specific unknown“) und periphere („universal quantification“ und „specific known“) semantische Primitiva sowie die Stärke der Verbindung zwischen ihnen zu bestimmen. Die stärksten Verbindungen bestehen zwischen „existential quantification“ und „free choice“ sowie zwischen „specific unknown“ und „existential quantification“. Die häufigsten nicht-pronominalen Bedeutungen der ZIPs, die in der Dissertation von Fisun jedoch nur unsystematisch identifiziert wurden, sind die mit depreziativer Bewertung verbundenen Funktionen „mediocrity“, „unimportant“ und „distancing“, was mit den Resultaten der Dissertation von Rybová und den Beobachtungen in der Literatur übereinstimmt.
Die abschließende Analyse der erstellten Karten lieferte wichtige Erkenntnisse für die Theorien der Grammatikalisierung der IPs und der Lizenzierung der IPs. Erstens wurden Korrelationen zwischen einzelnen semantisch-etymologischen Typen der präindefiniten Konstruktionen und der indefiniten bzw. post-indefiniten Semantik festgestellt. Zweitens wurden Zusammenhänge zwischen semantischen Primitiva und einzelnen Kontexten nachgewiesen. Zugleich wurde deutlich, dass die vorherrschende Vorstellung über die Lizenzierung der einzelnen Typen von IPs nicht mit den gewonnenen Frequenzdaten übereinstimmt. Zum einen ist die Lizenzierung nicht kategorial, sondern in Begriffen relativer Frequenz zu beschreiben: Frequente IPs werden in allen möglichen Kontexten verwendet, allerdings mit unterschiedlicher Häufigkeit. Zum anderen ist es entgegen der in der Literatur verbreiteten Meinung nicht möglich, die Semantik der meisten IPs allein auf der Grundlage ihrer Verteilung zu bestimmen. Der Grund dafür ist nicht nur die regelmäßig zu beobachtende „ungrammatische“ Verwendung der Reihen in für sie „untypischen“ Kontexten, sondern auch die extreme Polyfunktionalität der beschriebenen Einheiten. Die durchgeführten Clusteranalysen der ZIPs nach Semantik und Verwendungskontexten bestätigten dieses Ergebnis und ermöglichten es, Gruppen ähnlicher ZIPs in verschiedenen slavischen Sprachen zu identifizieren.
Dissertation von Martina Rybová „Die Beziehung zwischen Evaluativität und Indefinitheit am Beispiel der zusammengesetzten Indefinitpronomina im Tschechischen“ (co-tutelle mit UK Prag, Disputation am 29.11.2023 in Prag)
Indefinitheit und Evaluativität wurde im Rahmen der Promotionsschrift von Martina Rybová behandelt. Der Kern der Arbeit stellt eine korpusbasierte Fallstudie der Indefinitpronomina im Tschechischen dar. Dem Thema, inwieweit Indefinitpronomina außer einer unbestimmten Referenz zum Ausdruck einer evaluativen Bedeutung dienen können, wurde bisher kaum Aufmerksamkeit gewidmet, einige Arbeiten beschränken sich nur auf einzelne Bemerkungen. Damit diese Beziehung festgestellt werden kann, wird von der Behauptung vieler Evaluativitätsforscher ausgegangen, dass sich die Ausdrücke mit einer solchen Funktion in einer Aussage oder in einem Kontext anhäufen können. Infolgedessen wird hier ein neuer methodologischer Ansatz, eine sog. lexikographigesteuerte Kollokationsanalyse, vorgeschlagen. Diese besteht in einem Vergleich der in ausgewählten Wörterbüchern des Tschechischen beschriebenen Bedeutung von Kollokatoren eines Indefinitpronomens mit der Bedeutung, welche solche Kollokatoren in Verbindung mit dem jeweiligen Indefinitpronomen tragen. Außerdem werden auch einige morphosyntaktische Strukturen untersucht, in denen diese Verbindung typischerweise vorkommt. In Bezug auf die lexikographische Definition eines Kollokators des Indefinitpronomens sowie in Bezug auf die eigentliche Verbindung von diesen beiden wird dem jeweiligen Ausdruck ein Wert auf der vordefinierten Evaluativitätsskala zugeordnet. Die Untersuchung wird bei 11 ausgewählten Indefinitpronomina mit einem unterschiedlichem Grammatikalisierungsstatus durchgeführt. Die Kollokationsanalyse selbst basiert auf den Daten aus dem Webkorpus csTenTen v17.
Anhand der Ergebnisse wird festgestellt, dass es zwischen einer indefiniten und einer evaluativen Bedeutung einen Zusammenhang gibt. Bei den meisten Indefinitpronomina wird eine Tendenz zum Vorkommen in einer negativ evaluativen Umgebung sowie eine Fähigkeit festgestellt, die evaluative oder neutrale Bedeutung des Kontextes in eine eher negative Richtung zu steuern. Dies könnte so interpretiert werden, dass ein unbestimmtes und/oder unbestimmbares Objekt, eine solche Situation, Zeit oder Ort zumeist negativ empfunden wird. Weiterhin wird gemäß der Forschungsfragen und Ziele der Dissertation bestätigt, dass diese Eigenschaften der Indefinitpronomina nicht von ihrem Grammatikalisierungsgrad abhängig sind. Dessen ungeachtet wird bei einigen Indefinitpronomina eine klare Bevorzugung eines neutralen Kontextes beobachtet, wobei sie auch keinen Einfluss auf seine Interpretation zu haben scheinen. Darüber hinaus bietet die Arbeit eine Übersicht der unterschiedlichen theoretischen Ansätze zur Evaluativität und eine erneuerte Inventarisierung der tschechischen Indefinitpronomina, welche dann den Ausgangspunkt für die Auswahl der untersuchten Einheiten darstellt. Außer den neuen Erkenntnissen hinsichtlich der evaluativen Bedeutung der Indefinitpronomina und ihrer Rolle bei einem Polaritätswechsel auf der Skala bringt die Arbeit eine neue Methode zur Untersuchung eines Verhältnisses zwischen zwei komplexen semantischen Systemen. Daher bietet die Arbeit auch die Grundlagen für die zukünftigen Erforschungen auf diesem oder einigen anderen angrenzenden Gebieten sowie ein Dataset und Ausgangshypothesen für mögliche psycholinguistische Experimente.
Masterarbeit von Irina Maykova (2023)
Die Arbeit ist den stilistischen Eigenschaften der RU ZIPs gewidmet. Die Arbeit überprüft die in der wissenschaftlichen Literatur erwähnte These, dass ZIPs überwiegend für die Umgangssprache typisch sind. Als Material der Untersuchung dienten Daten des russischen Nationalkorpus. Die Korpusanalyse lieferte die folgenden Resultate: i. Die Modifikatoren, die als ‚umgangssprachlich‘ oder ‚prostorečnoe‘ markiert sind, unterscheiden sich tatsächlich von den stilistisch neutralen in Bezug auf ihrer Verteilung kaum: dem überwiegenden Zuschreiben zum Funktionalstil der gesprochenen Sprache kann man nicht zustimmen. ii. Die Korpusanalyse zeigte, dass es keinen deutlichen Unterschied gibt zwischen den ZIPs mit einer emotionaler Bedeutungskomponente und diejenige ohne einer solchen. iii. Es konnte kein deutlicher Unterschied zwischen den kodifizierten und nichtkodifizierten ZIPs in Bezug auf ihre funktionalstilistische Zugehörigkeit festgestellt werden. iv. Die Hypothese, dass ZIPs überwiegend in gesprochener Sprache vorkommen, wurde nicht bestätigt. Wie die Analyse gezeigt hat, treten ZIPs überwiegend im Stil der mündlichen Sprache sowie im Stil der schönen Literatur auf, wobei die Tendenz der Verwendung von ZIPs im Stil der schönen Literatur deutlich zu erkennen ist. Eine klare stilistische Zugehörigkeit aller ZIPs lässt sich bei der Analyse nicht bestimmen; das Tendieren einzelner ZIPs (ни на есть, бы то ни был, ни попадя, безразлично, бог весть) zur Verwendung fast ausschließlich in einem Funktionalstil ist jedoch deutlich zu erkennen.
Publikationen, Vorträge und Materialien
Publikationen, Vorträge, Vorarbeit
Qualifikationsarbeiten
Fisun, R. (in Vorbereitung). Zusammengesetzte Indefinitpronomen in den slavischen Sprachen. Dissertation, Universität Regensburg.
Maykova, I. (externer Link, öffnet neues Fenster) (2023). Zur Funktionalstilistik ausgewählter Indefinitpronomen im Russischen. Masterarbeit, Universität Regensburg.
Rybová, M. (externer Link, öffnet neues Fenster)(2025). Evaluativität und Indefinitheit: Indefinitpronomina im Tschechischen. Heidelberg: Winter.
Publikationen
Fisun, R., & Hansen, B. (externer Link, öffnet neues Fenster) (2025). A corpus-based study on the inventory and grammaticalisation of compound indefinite pronouns in Croatian. Die Welt der Slaven, 69(2), 293–330.
Fisun, R. S. (externer Link, öffnet neues Fenster) (2025). Ešče raz o licenzirovanii slavjanskich neopredelennych mestoimenij: korpusnoe issledovanie. In: D. Bunčić (Hrsg.), Deutsche Beiträge zum 17. Internationalen Slavistikkongress, Paris 2025: Resümees, 81–84. Köln: Universitäts- und Stadtbibliothek.
Fisun, R. S. (externer Link, öffnet neues Fenster)(2024). Možno li posčitat´ neopredelennye mestoimenija? In: E. S. Uzenëva und O. V. Chavanova (Hrsg.), Slavjanskij mir: obščnost´ i mnogoobrazie. Materialy konferencii molodych učenych v ramkach Dnej slavjanskoj pis´mennosti i kul´tury (21–22 maja 2024 g.), 196–202. Moskau: Institut slavjanovedenija RAN.
Fisun, R. S. (externer Link, öffnet neues Fenster) (2022). Inventar´ modifikatorov i istočniki grammatikalizacii sostavnych neopredelennych mestoimenij v slavjanskich jazykach. In: E. S. Uzenëva und O. V. Chavanova (Hrsg.), Slavjanskij mir: obščnost´ i mnogoobrazie. Tezisy konferencii molodych učenych v ramkach Dnej slavjanskoj pis´mennosti i kul´tury. 24–25 maja 2022 g., 80–85. Moskau.
Fisun, R. (externer Link, öffnet neues Fenster)(2019). Zusammengesetzte Indefinitpronomen im Ukrainischen. In: H. Macjuk, I. Mytnik und O. Novikova (Hrsg.), Mova v suspil’stvi: semantyka, syntaktyka, prahmatyka, 85–99. Warschau.
Fisun, R. S. (externer Link, öffnet neues Fenster) (2019). Sostavnye neopredelennye mestoimenija v ukrainskom jazyke. In: Naukovyj časopys Nacional´noho pedahohičnoho universytetu imeni M. P. Drahomanova. Serija 10: Problemy hramatyky i leksykolohiji ukrajins´koji movy: zbirnyk naukovych prac´, 14, 117–126. Kyjiv: NPU imeni M. P. Drahomanova.
Rybová, M. (2018). Konstrukce ne a ne + infinitiv a její německé protějšky. In: A. Butašová, V. Benko und Z. Puchovská (Hrsg.), ARANEA 2018: Web Corpora as a Language Training Tool. Sammelband der Konferenz Aranea 2018, 23.–24.11.2018, Bratislava, 125–133. Bratislava: Univerzita Komenského v Bratislave, Filozofická fakulta.
Präsentationen
Hansen B. & Fisun, R. (externer Link, öffnet neues Fenster) (2025) Zusammengesetzte Indefinitpronomen in den slavischen Sprachen: Korpusbasierte Untersuchung der Grammatikalisierung und Distribution. Gastvortrag am Institut für Slawistik der Alpen-Adria-Universität Klagenfurt. 04.12.2025. Klagenfurt, Österreich.
Fisun, R. (2025) Составные местоимения в славянских языках: семантическое картирование и другие аспекты. Gastvortrag an der UiT The Arctic University of Norway, Forschungsgruppe CLEAR. 07.10.2025. Tromsø, Norwegen.
Fisun, R. (externer Link, öffnet neues Fenster) (2025) Еще раз о лицензировании славянских неопределенных местоимений: корпусное исследование. Vortrag auf dem XVII. Internationalen Slavistenkongress. 25.–30.08.2025. Paris, Frankreich.
Fisun, R. (externer Link, öffnet neues Fenster) (2025) Korpusbasierte Erfassung des Grammatikalisierungsgrades von Indefinitpronomen. Vortrag im Graduiertenkolloquium (Leitung: Prof. Dr. Johann-Mattis List, Lehrstuhl für Multilinguale Computerlinguistik). 27.05.2025. Universität Passau.
Fisun, R. (externer Link, öffnet neues Fenster) (2025) Что лицензирует неопределенные местоимения? Славянский взгляд на лицензирующие контексты. Vortrag auf der Konferenz „Славянский мир: общность и многообразие“. 20.05.2025. Moskau, Russland.
Fisun, R. (externer Link, öffnet neues Fenster) (2024) Можно ли посчитать неопределенные местоимения?. Vortrag auf der Konferenz „Славянский мир: общность и многообразие“. 21.–22.05.2024. Moskau, Russland.
Fisun, R. (2022) Semantische Kartierung der zusammengesetzten Indefinitpronomen in den slavischen Sprachen. Vortrag im Linguistischen Kolloquium der Fakultät für für Sprach-, Lteratur- und Kulturwissenschaften. 21.12.2022. Regensburg
Fisun, R. (2022) Semantische Analyse und kontextuelle Distribution der zusammengesetzten Indefinitpronomen im Russischen, Ukrainischen und Polnischen. Vortrag auf dem „14. Deutschen Slavistiktag“. 21.–24. September 2022. Ruhr-Universität Bochum
Rybová, M. (2022): Wenn Bewertung und Indefinitheit wie Pech und Schwefel zusammenhalten: eine Kollokationsanalyse der zusammengesetzten Indefinitpronomina im Tschechischen. 14. Deutscher Slavistiktag, Bochum, 21.–24.09.2022.
Rybová, M. (2022): When evaluativity and indefiniteness are as thick as thieves: some remarks on the evaluativity of compound indefinite pronouns in Czech. International Conference on Intercultural Pragmatics and Communication (INPRA9), Brisbane, Australien, 21.–23.06.2022.
Fisun, R (2022) Inventar´ modifikatorov i istočniki grammatikalizacii sostavnych neopredelennych mestoimenij v slavjanskich jazykach. Vortrag auf Konferenz „Slavjanskij mir: obščnost´ i mnogoobrazie“. 24.–25. Mai 2022. Moskau, Russland
Rybová, M. (2022): Weiß der Geier was sie damit meinen: Zur Evaluativität der zusammengesetzten Pronomina im Tschechischen. Gastvorträge des Slavistischen Seminars, Tübingen, 27.04.2022.
Rybová, M. (2022): They go together like a horse and carriage: On evaluative prosody of compound indefinite pronouns in Czech. Workshop on Czech in empirical and comparative perspectives, Jena, 04.–05.03.2022.
Fisun R. Grammatikalisierungsgrad der zusammengesetzten Indefinitpronomen in den slavischen Sprachen. Vortrag im „online-Kolloquium Slavistische Linguistik“. 3. Dezember 2021
Rybová, M. (2021): Zur Beziehung zwischen Evaluativität und Indefinitheit am Beispiel des zusammengesetzten Indefinitpronomens mit dem Modifikator bůhví-. Online-Kolloquium Slavistische Linguistik, 18.06.2021.
Rybová, M. (2021): Some remarks on the relation of evaluativity and indefiniteness on the example of Czech compound indefinite pronouns. 7th Young Linguists’ Meeting in Poznań, online, 23.–25.04.2021
Fisun R. Inventarisierung der zusammengesetzten Indefinitpronomen in den slavischen Sprachen. Vortrag im „online-Kolloquium Slavistische Linguistik“. 15. Januar 2021
Hansen B. & R. Fisun (2019) (externer Link, öffnet neues Fenster) Neopredelennye mestoimenija: ot konteksta k semantičeskoj karte. Konferenz „Russkij jazyk: konstrukcionnye i leksiko-semantičeskie podchody“. 3–5.10.2019. Sankt Petersburg, Russland
Fisun, R. (2019) (externer Link, öffnet neues Fenster) O značenii nekotorych russkich sostavnych mestoimennych serij v sravnenii s analogičnymi v ukrainskom i pol´skom. VI. Meždunarodnyj kongress issledovatelej russkogo jazyka Russkij jazyk: istoričeskie sud ́by i sovremennost ́. 19–24.03.2019. Moskau, Russland
Fisun, R. (2019) (externer Link, öffnet neues Fenster) Neue semantische Karte der Indefinitpronomen. 13. Deutscher Slavistentag 24–26.09.2019. Trier, Deutschland
Fisun, R. (2019) (externer Link, öffnet neues Fenster) Ob istočnikach grammatikalizacii sostavnych neopredelennych mestoimenij v ukrainskom, russkom i pol´skom jazykach v svjazi s ich značenijami. Konferenz „Ukraїns´kij movnij svіt u slov’jans´komu vsesvіtі“. 28–29.11.2019. Kiew, Ukraine
Vorarbeiten
Jurkiewicz-Rohrbacher, E., B. Hansen & Z. Kolaković (2017) (externer Link, öffnet neues Fenster) Web Corpora – the best possible solution for tracking rare phenomena in underressourced languages: clitics in Bosnian, Croatian and Serbian. In: P. Bański et al. (eds.) Proceedings of the Workshop on Challenges in the Management of Large Corpora and Big Data and Natural Language Processing, 49–55. Mannheim.
Fisun, R. S. (2016) (externer Link, öffnet neues Fenster) Ob opredelënnosti neopredelënnych mestoimenij. In: Vestnik Moskovskogo gosudarstvennogo oblastnogo universiteta. Serija: Russkaja filologija 5, 158–170.
Fisun, R. S. (2016) (externer Link, öffnet neues Fenster) Ob ispol'zovanii semantičeskogo kartirovanija v opisanii mestoimennogo komponenta značenija russkich sostavnych mestoimenij. In: Filologieskie nauki. Voprosy teorii i praktiki 11, Bd. 2, 148–158.
Hansen, B. (2006) (externer Link, öffnet neues Fenster) Mapy semantyczne w konfrontacji językowej. In: V. Koseska-Toszewa & R. Roszko (eds.) Semantyka a konfrontacja językowa. Bd. 3., 141–151.Warszawa.
Hansen, B. (2004) The boundaries of grammaticalization. The case of modals in Russian, Polish and Serbian/Croatian. In: W. Bisang, N. P. Himmelmann & B. Wiemer (eds.) What makes grammaticalization? A look from its fringes and its components, 245–271. Berlin
Hansen, B. (2001) (externer Link, öffnet neues Fenster) Das Modalauxiliar im Slavischen. Grammatikalisierung und Semantik im Russischen, Polnischen, Serbischen/Kroatischen und Altkirchenslavischen (Slavolinguistica 2). München.